Method Overview

GUIDES consists of three main components: (1) Instructor - a fine-tuned vision-language model that generates contextual instructions based on visual observations, (2) Guidance Module - an auxiliary network that encodes instructions into guidance embeddings and injects them into the policy's latent space, and (3) Reflector - an LLM-based component that monitors confidence and refines actions through reasoning when needed.
Architecture
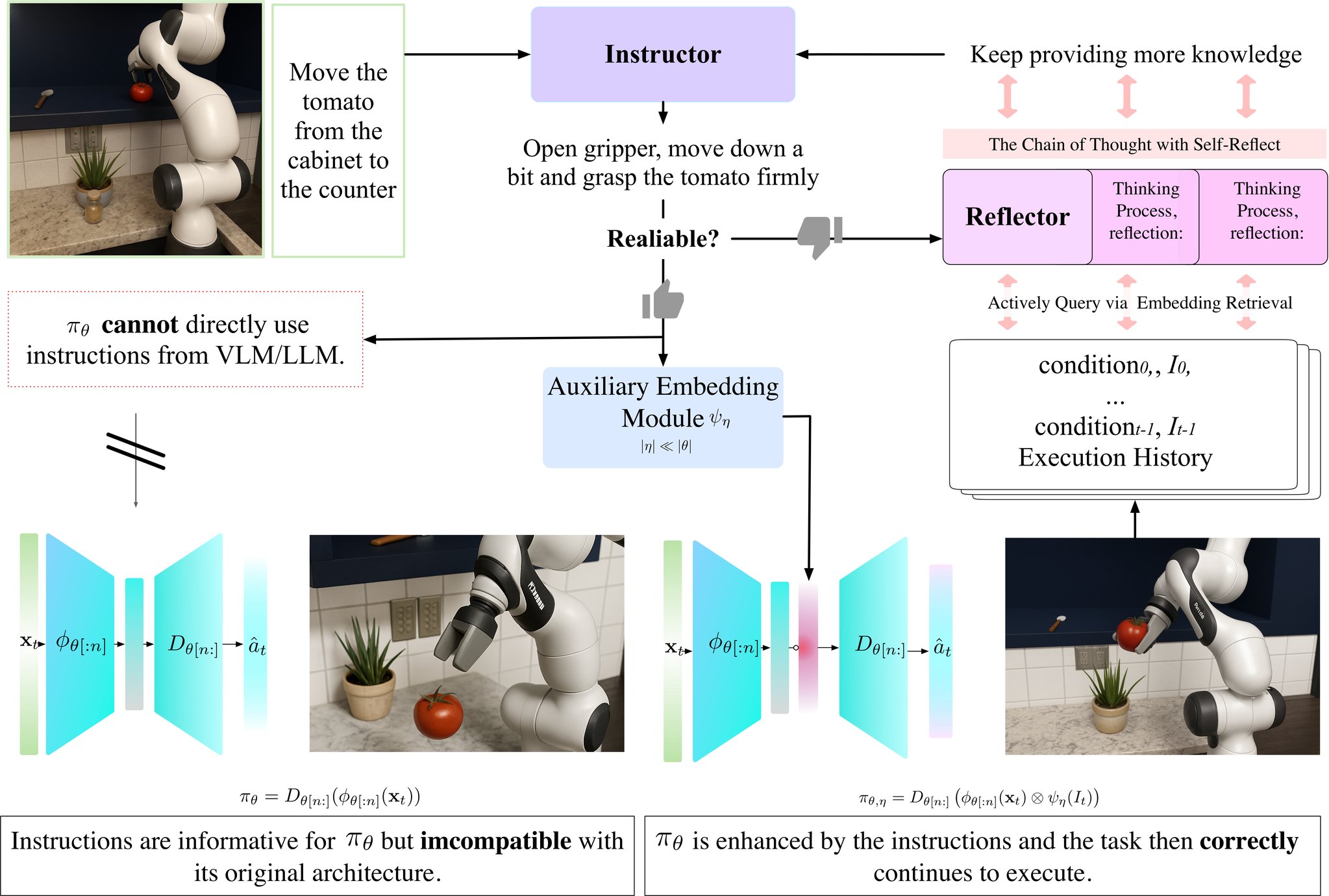
The GUIDES framework seamlessly integrates with existing pre-trained policies. The Instructor processes visual observations to generate natural language instructions, which are then encoded into guidance embeddings by the auxiliary module. These embeddings are injected into the policy's latent representation, enabling semantic-aware decision making while preserving the original policy's learned behaviors.
Experimental Results
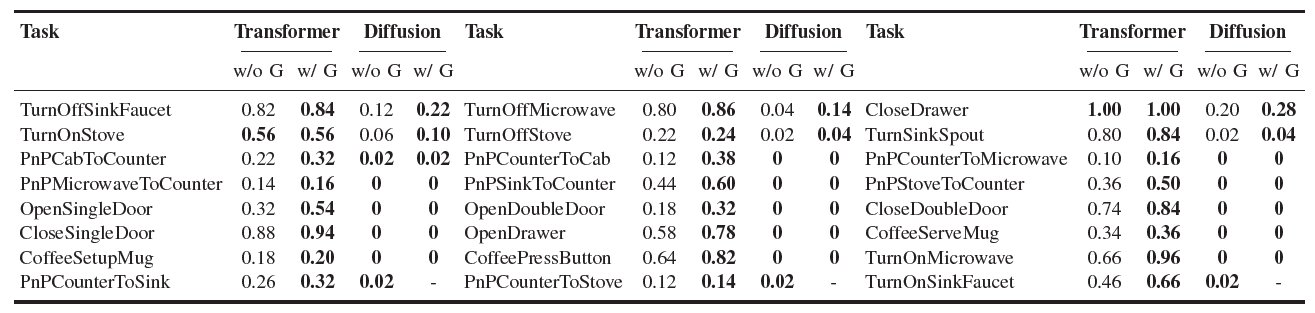
GUIDES demonstrates consistent improvements across diverse policy architectures in the RoboCasa simulation environment. The framework shows substantial gains in task success rates while maintaining computational efficiency. Results indicate that semantic guidance significantly enhances the policy's ability to understand and execute complex manipulation tasks.
Real-world Deployment
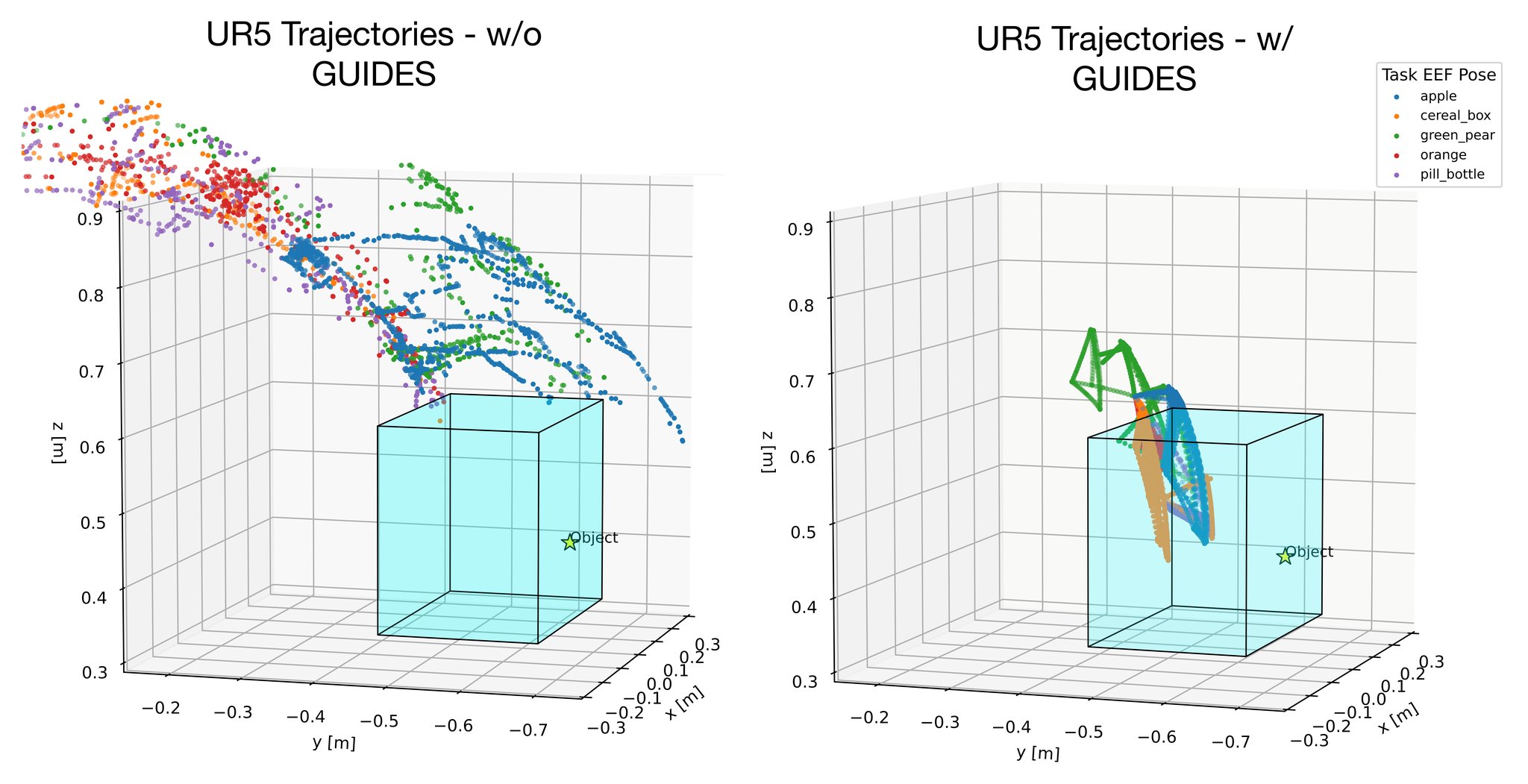
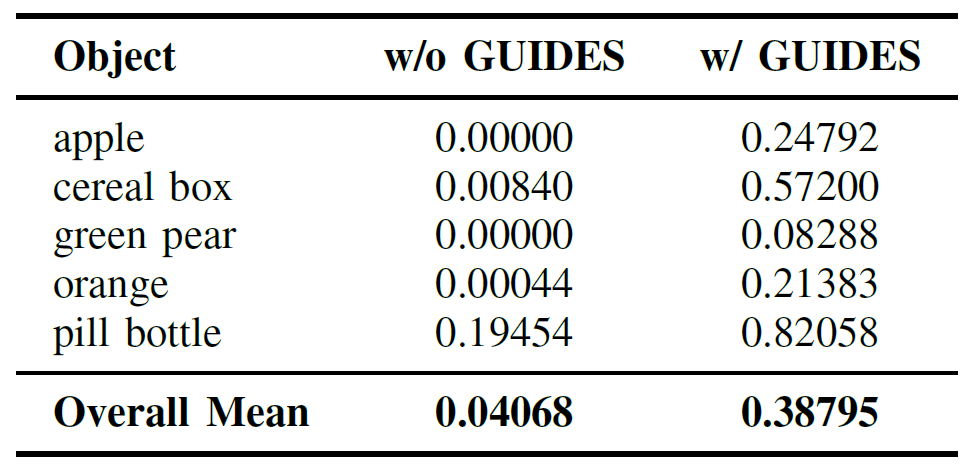
Real-world validation on a UR5 robot demonstrates GUIDES' practical applicability. The framework enhances motion precision for critical sub-tasks such as grasping, showing that the semantic guidance translates effectively from simulation to real-world scenarios.
t-SNE Visualization of Guidance Embeddings
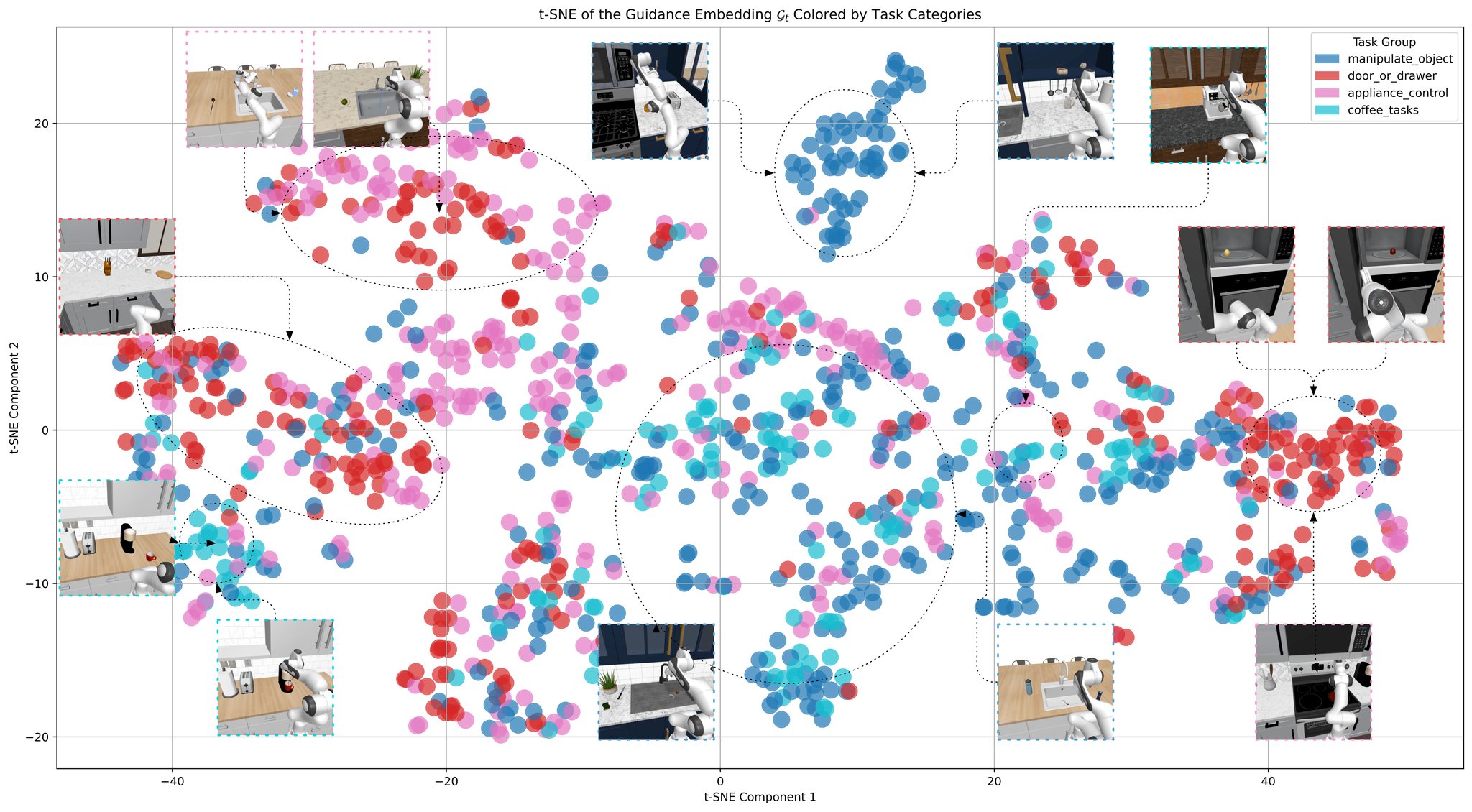
The resulting t-SNE plot reveals distinct and interpretable clusters of the guidance embeddings. For example, object manipulation tasks form a clear central group, while appliance-control tasks cluster separately toward the right. At a finer level, specific tasks maintain semantically structured latent spaces. This demonstrates that GUIDES effectively distills instructions into compact, semantically meaningful representations.